Graham: Difference between revisions
(Created section 'Site-specific policies', imported content from Known Issues) |
(Marked this version for translation) |
||
| Line 34: | Line 34: | ||
[[Transferring_data|Transfering data]] | [[Transferring_data|Transfering data]] | ||
= Site-specific policies = | = Site-specific policies = <!--T:39--> | ||
<!--T:40--> | |||
By policy, Graham's compute nodes cannot access the internet. If you need an exception to this rule, | By policy, Graham's compute nodes cannot access the internet. If you need an exception to this rule, | ||
contact [[Technical Support|technical support]] and describe what you need to access and why. | contact [[Technical Support|technical support]] and describe what you need to access and why. | ||
<!--T:41--> | |||
Crontab is not offered on Graham. | Crontab is not offered on Graham. | ||
Revision as of 17:44, 21 September 2018
| Availability: In production since June 2017 |
| Login node: graham.computecanada.ca |
| Globus endpoint: computecanada#graham-dtn |
| Data mover node (rsync, scp, sftp,...): gra-dtn1.computecanada.ca |
GRAHAM is a heterogeneous cluster, suitable for a variety of workloads, and located at the University of Waterloo. It is named after Wes Graham, the first director of the Computing Centre at Waterloo. It was previously known as "GP3" and is still identified as such in the 2017 RAC documentation.
The parallel filesystem and external persistent storage (NDC-Waterloo) are similar to Cedar's. The interconnect is different and there is a slightly different mix of compute nodes.
The Graham system is sold and supported by Huawei Canada, Inc. It is entirely liquid cooled, using rear-door heat exchangers.
Site-specific policies[edit]
By policy, Graham's compute nodes cannot access the internet. If you need an exception to this rule, contact technical support and describe what you need to access and why.
Crontab is not offered on Graham.
Attached storage systems[edit]
| Home space | |
| Scratch space 3.6PB total volume Parallel high-performance filesystem |
|
| Project space External persistent storage |
|
High-performance interconnect[edit]
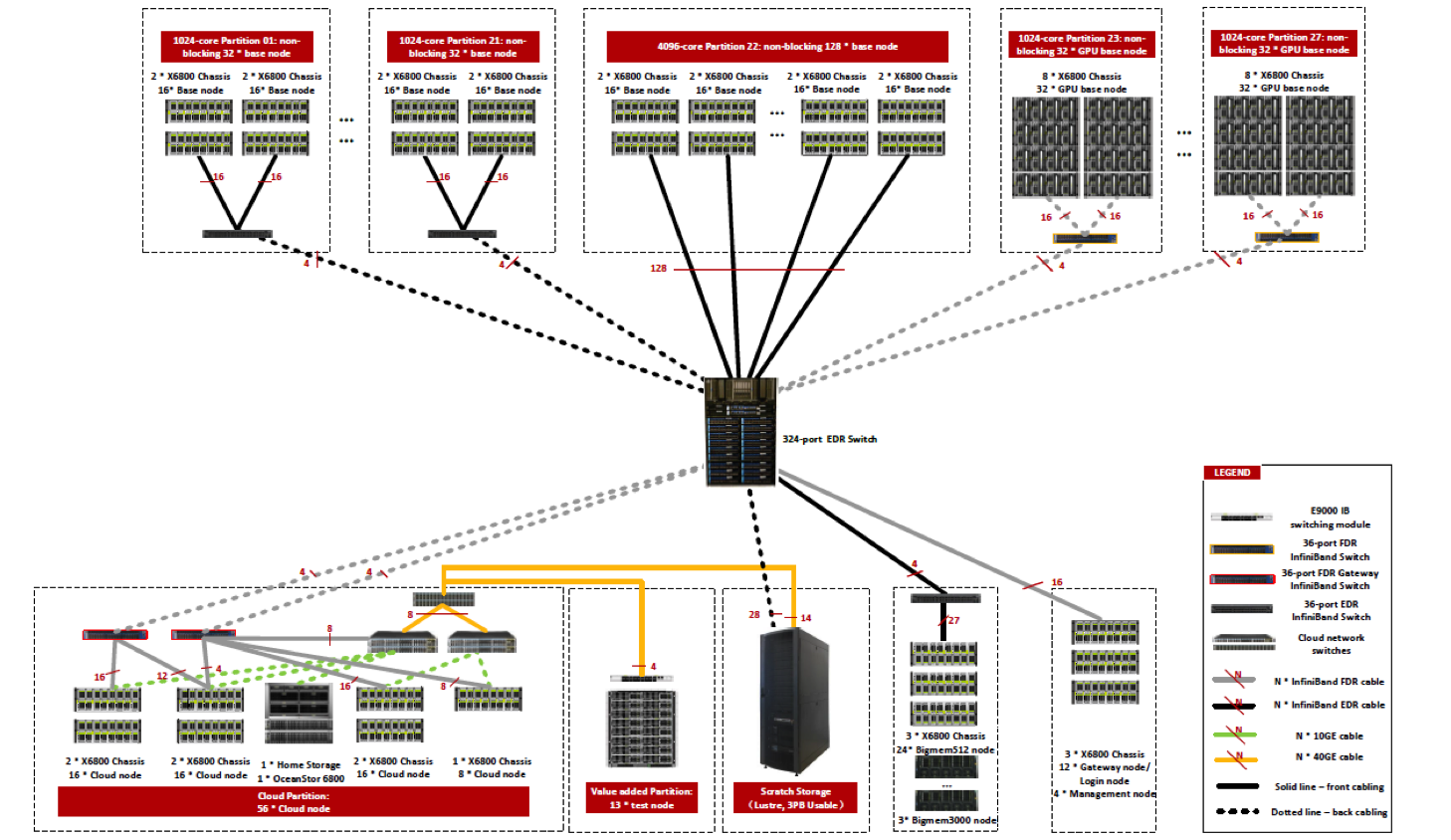
Mellanox FDR (56Gb/s) and EDR (100Gb/s) InfiniBand interconnect. FDR is used for GPU and cloud nodes, EDR for other node types. A central 324-port director switch aggregates connections from islands of 1024 cores each for CPU and GPU nodes. The 56 cloud nodes are a variation on CPU nodes, and are on a single larger island sharing 8 FDR uplinks to the director switch.
A low-latency high-bandwidth Infiniband fabric connects all nodes and scratch storage.
Nodes configurable for cloud provisioning also have a 10Gb/s Ethernet network, with 40Gb/s uplinks to scratch storage.
The design of Graham is to support multiple simultaneous parallel jobs of up to 1024 cores in a fully non-blocking manner.
For larger jobs the interconnect has a 8:1 blocking factor, i.e., even for jobs running on multiple islands the Graham system provides a high-performance interconnect.
Graham high performance interconnect diagram
{kind=link}
Node types and characteristics[edit]
A total of 36,160 cores and 320 GPU devices, spread across 1,127 nodes of different types.
Processor type: All nodes except bigmem3000 have Intel E5-2683 V4 CPUs, running at 2.1 GHz
GPU type: P100 12g
| count | Node type | cores | available memory | hardware detail |
|---|---|---|---|---|
| 884 | base "128G" | 32 | 125G or 128000M | two Intel E5-2683 v4 "Broadwell" at 2.1Ghz; 960GB SATA SSD |
| 24 | large "512G" | 32 | 502G or 514500M | (same as base nodes) |
| 56 | large/cloud | 32 | 250G or 256500M | (same as base nodes) may be reserved for cloud use |
| 3 | bigmem3000 "3T" | 64 | 3022G or 3095000M | like base nodes but four E7-4850 v4 "Broadwell" CPUs at 2.1Ghz |
| 160 | GPU | 32 | 124G or 127518M | like base nodes but also two NVIDIA P100 Pascal GPUs (12GB HBM2 memory, 1.6TB NVMe SSD |
Best practice for local on-node storage is to use the temporary directory generated by Slurm, $SLURM_TMPDIR. Note that this directory and its contents will disappear upon job completion.
Note that the amount of available memory is less than the "round number" suggested by hardware configuration. For instance, "base" nodes do have 128 GiB of RAM, but some of it is permanently occupied by the kernel and OS. To avoid wasting time by swapping/paging, the scheduler will never allocate jobs whose memory requirements exceed the specified amount of "available" memory. Please also note that the memory allocated to the job must be sufficient for IO buffering performed by the kernel and filesystem - this means that an IO-intensive job will often benefit from requesting somewhat more memory than the aggregate size of processes.