Graham
| Disponibilité : en production depuis juin 2017 |
| Nœud frontal (login node) : graham.calculcanada.ca |
| Point de chute Globus : computecanada#graham-dtn |
| Nœud de copie (rsync, scp, sftp,...) : gra-dtn1.calculcanada.ca |
Graham est une grappe hétérogène adaptée pour une grande variété de types de tâches; elle est située à l'Université de Waterloo. Son nom rappelle Wes Graham, premier directeur du Computing Centre de l'Université de Waterloo.
Les systèmes de fichiers parallèles et le stockage persistant (NDC-Waterloo) sont semblables à ceux de Cedar. L'interconnexion n'est pas la même et il y a des proportions différentes du nombre de chaque type de nœuds de calcul.
La grappe Graham a été acquise de Huawei Canada au début de 2017. Un système de refroidissement liquide utilise des échangeurs de chaleur à même les portes arrière.
Voyez de courtes vidéos sur les notions de base pour l'utilisation de Graham.
Particularités
- Selon notre politique, les nœuds de calcul de Graham n'ont pas accès à l'internet. Pour y faire exception, contactez le soutien technique avec les renseignements suivants:
Adresse IP : Port(s) : Protocole : TCP ou UDP Contact : Date de fin :
Avant de mettre fin au lien internet, nous communiquerons avec la personne-ressource pour vérifier si la règle est toujours nécessaire.
- Crontab n'est pas offert sur Graham.
- Chaque tâche devrait avoir une durée minimum d'une heure et de cinq minutes pour une tâche de test.
- Un utilisateur ne peut avoir plus de 1000 tâches à la fois en exécution et en attente. Dans le cas d'un lot de tâches (array job), chacune est comptée individuellement.
Stockage
| espace /home Volume total de 64To |
|
| espace /scratch Volume total de 3.6Po Système de fichiers parallèle de haute performance |
|
| espace /project Volume total de 16Po Stockage persistant externe |
|
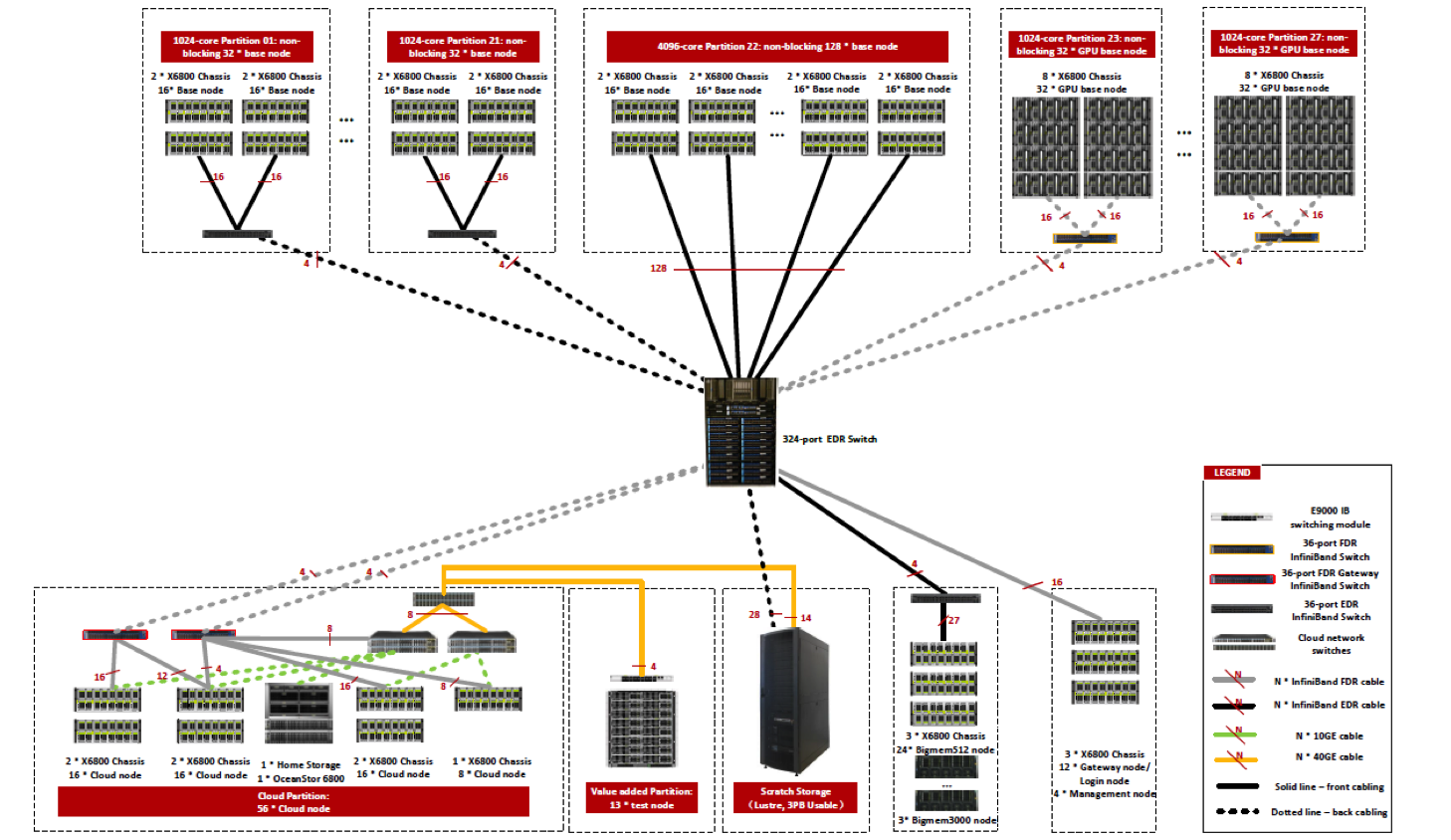
Interconnexion haute performance
Interconnexion InfiniBand Mellanox FDR (56Go/s.) et EDR (100Go/s.). FDR sert aux nœuds GPU et aux nœuds infonuagiques; tous les autres types de nœuds utilisent EDR. Un répartiteur (director switch) central de 324 ports rassemble les connexions des ilots CPU et GPU de 1024 cœurs. Les 56 nœuds infonuagiques se situent sur les nœuds CPU; ils sont regroupés sur un plus grand ilot et partagent 8 liens FDR vers le répartiteur.
Une interconnexion non bloquante (InfiniBand fabric) à haute bande passante et faible latence connecte tous les nœuds et le stockage /scratch.
Les nœuds configurés pour le service infonuagique possèdent aussi un réseau Ethernet 10Go/s. et des liens de 40Go/s. vers le stockage /scratch.
L'architecture de Graham a été planifiée pour supporter de multiples tâches parallèles jusqu'à 1024 cœurs grâce à une réseautique non bloquante.
Pour les tâches plus imposantes, le facteur de blocage est de 8:1; même pour les tâches exécutées sur plusieurs ilots, l'interconnexion est de haute performance.
Diagramme des interconnexions pour Graham
{kind=link}
Visualisation
Graham offre des nœuds dédiés pour la visualisation qui permettent uniquement les connexions VNC (gra-vdi.calculcanada.ca). Pour l'information sur comment les utiliser, voyez la page VNC.
Caractéristiques des nœuds
41,548 cœurs et 520 GPU sur 1,185 nœuds de différents types. TurboBoost est activé sur tous les nœuds.
| nœuds | cœurs | mémoire disponible | CPU | stockage | GPU |
|---|---|---|---|---|---|
| 903 | 32 | 125G ou 128000M | 2 x Intel E5-2683 v4 Broadwell @ 2.1GHz | SSD SATA 960Go | - |
| 24 | 32 | 502G ou 514500M | 2 x Intel E5-2683 v4 Broadwell @ 2.1GHz | SSD SATA 960Go | - |
| 56 | 32 | 250G ou 256500M | 2 x Intel E5-2683 v4 Broadwell @ 2.1GHz | SSD SATA 960Go | - |
| 3 | 64 | 3022G ou 3095000M | 4 x Intel E7-4850 v4 Broadwell @ 2.1GHz | SSD SATA 960Go | - |
| 160 | 32 | 124G ou 127518M | 2 x Intel E5-2683 v4 Broadwell @ 2.1GHz | SSD NVMe 1.6T | 2 x NVIDIA P100 Pascal (mémoire HBM2 12Go) |
| 7 | 28 | 178G ou 183105M | 2 x Intel Xeon Gold 5120 Skylake @ 2.2GHz | SSD NVMe 4.0T NVMe | 8 x NVIDIA V100 Volta (mémoire HBM2 16Go) |
| 2 | 40 | 377G ou 386048M | 2 x Intel Xeon Gold 6248 Cascade Lake @ 2.5GHz | SSD NVMe 5.0To | 8 x NVIDIA V100 Volta (mémoire HBM2 32Go), NVLINK |
| 6 | 16 | 192G ou 196608M | 2 x Intel Xeon Silver 4110 Skylake @ 2.10GHz | SSD SATA 11.0To | 4 x NVIDIA T4 Turing (mémoire GDDR6 16Go) |
| 30 | 44 | 192G ou 196608M | 2 x Intel Xeon Gold 6238 Cascade Lake @ 2.10GHz | SSD MVME 5.8To | 4 x NVIDIA T4 Turing (mémoire GDDR6 16Go) |
| 72 | 44 | 192G ou 196608M | 2 x Intel Xeon Gold 6238 Cascade Lake @ 2.10GHz | SSD SATA 879Go | - |
La plupart des applications fonctionneront soit avec des nœuds Broadwell, Skylake ou Cascade Lake et les différences en termes de performance devraient être minimes à comparer avec les temps d'attente. Nous recommandons donc de ne pas sélectionner un type de nœud particulier pour vos tâches. Si nécessaire, pour les tâches avec CPU il n'y a que deux contraintes disponibles; utilisez --constraint=broadwell ou --constraint=cascade (voir comment spécifier l'architecture CPU).
Pour le stockage local sur nœud, il est recommandé d'utiliser le répertoire temporaire $SLURM_TMPDIR généré par Slurm. Ce répertoire avec son contenu est supprimé à la fin de l'exécution de la tâche.
Remarquez que la quantité de mémoire disponible est moindre que la valeur arrondie suggérée par la configuration matérielle. Par exemple, les nœuds de type base 128G ont effectivement 128Gio de mémoire vive, mais une certaine quantité est utilisée en permanence par le noyau (kernel) et le système d'exploitation. Pour éviter la perte de temps encourue par le swapping ou le paging, l'ordonnanceur n'allouera jamais une tâche dont les exigences dépassent la quantité de mémoire disponible indiquée dans le tableau ci-dessus. Notez aussi que la mémoire allouée pour la tâche doit être suffisante pour les lectures et écritures dans la mémoire tampon effectuées par le noyau et le système de fichiers; lorsque ces opérations sont nombreuses, il est préférable de demander plus de mémoire que la quantité totale requise par les processus.
GPU
Les trois générations de GPU Tesla, de la plus ancienne à la plus récente, sont :
- P100 Pascal
- V100 Volta (incluant 2 nœuds avec interconnexion NVLINK)
- T4 Turing
P100 est la carte haute performance de NVIDIA pour usage général. V100 lui succède et offre deux fois plus de performance pour les calculs standards et huit fois plus de performance pour les calculs en apprentissage profond qui peuvent utiliser ses unités de calcul avec cœurs Tensor. La carte T4 plus récente est adaptée aux tâches d'apprentissage profond; elle n'est pas efficace pour les calculs double précision, mais sa performance en simple précision est bonne; elle possède aussi des cœurs Tensor et peut traiter les calculs à précision réduite avec les entiers.
Nœuds GPU Pascal
Il s'agit des cartes GPU par défaut de Graham. Pour soumettre des tâches, voyez Ordonnancement Slurm des tâches avec GPU. Si vous demandez un GPU pour une tâche avec --gres=gpu:1 ou --gres=gpu:2, les cartes Pascal P100 lui seront assignées. La configuration de tâches pour ces cartes est relativement simple puisque tous les nœuds Pascal n'ont que deux GPU P100.
Nœuds GPU Volta
Graham a neuf nœuds GPU Volta au total :
- dans sept de ces nœuds, quatre GPU sont connectés à chaque socket CPU, à l'exception d'un nœud qui possède six GPU avec trois par socket;
- les deux autres nœuds ont une interconnexion NVLINK à large bande passante.
Les nœuds sont disponibles à tous les utilisateurs pour des durées d'exécution maximales de 7 jours.
Dans l'exemple suivant, le script soumet une tâche pour un des nœuds de 8 GPU. La commande module load fait en sorte que les modules compilés pour l'architecture Skylake soient utilisés. Remplacez nvidia-smi par la commande que vous voulez lancer.
IMPORTANT : Déterminez le nombre de CPU à demander en appliquant un ratio CPU/GPU de 3.5 ou moins sur des nœuds de 28 cœurs. Par exemple, si votre tâche doit utiliser 4 GPU, vous devriez demander au plus 14 cœurs CPU et pour utiliser 1 GPU, demander au plus 3 cœurs CPU. Les utilisateurs peuvent faire exécuter quelques tâches de test de moins d'une heure pour connaître le niveau de performance du code.
Les deux plus récents nœuds Volta ont 40 cœurs et le nombre de cœurs par GPU demandé doit être ajusté à la hausse selon le cas; une tâche peut par exemple utiliser 5 cœurs CPU par GPU. Ces nœuds sont aussi interconnectés par NVLINK ce qui est un grand avantage quand la bande passante entre GPU crée un goulot d’étranglement. Pour utiliser un de ces nœuds, il faut ajouter l’option --nodelist=gra1337 ou --nodelist=gra1338 au script de soumission de la tâche.
Exemple avec un seul GPU
#!/bin/bash
#SBATCH --account=def-someuser
#SBATCH --gres=gpu:v100:1
#SBATCH --cpus-per-task=3
#SBATCH --mem=12G
#SBATCH --time=1-00:00
module load arch/avx512 StdEnv/2018.3
nvidia-smi
Exemple avec un nœud entier
#!/bin/bash
#SBATCH --account=def-someuser
#SBATCH --nodes=1
#SBATCH --gres=gpu:v100:1
#SBATCH --cpus-per-task=3
#SBATCH --mem=12G
#SBATCH --time=1-00:00
module load arch/avx512 StdEnv/2018.3
nvidia-smi
Les nœuds Volta de Graham ont un disque local rapide qui devrait être utilisé si la tâche exige beaucoup d'opérations I/O. Dans la tâche, la variable d'environnement $SLURM_TMPDIR donne la localisation du répertoire temporaire sur le disque. Vous pouvez y copier vos fichiers de données au début du script avant d'exécuter le programme, et y copier vos fichiers de sortie à la fin du script. Comme tous les fichiers contenus dans $SLURM_TMPDIR sont supprimés quand la tâche est terminée, vous n'avez pas à le faire. Vous pouvez même créer des environnements virtuels Python dans cet espace temporaire pour améliorer l'efficacité.
Nœuds GPU Turing
Ces nœuds s'utilisent comme les nœuds Volta, sauf que vous devriez les demander en indiquant
--gres=gpu:t4:2
Dans cet exemple, on demande deux cartes T4 par nœud.