Graham
| Availability: In production since June 2017 |
| Login node: graham.computecanada.ca |
| Globus endpoint: computecanada#graham-dtn |
| Data mover node (rsync, scp, sftp,...): gra-dtn1.computecanada.ca |
GRAHAM is a heterogeneous cluster, suitable for a variety of workloads, and located at the University of Waterloo. It is named after Wes Graham, the first director of the Computing Centre at Waterloo.
The parallel filesystem and external persistent storage (NDC-Waterloo) are similar to Cedar's. The interconnect is different and there is a slightly different mix of compute nodes.
The Graham system is sold and supported by Huawei Canada, Inc. It is entirely liquid cooled, using rear-door heat exchangers.
Site-specific policies[edit]
By policy, Graham's compute nodes cannot access the internet. If you need an exception to this rule, contact technical support with the following information:
IP: Port/s: Protocol: TCP or UDP Contact: Removal Date:
We will follow up with the contact before removing to confirm if this rule is still required.
Crontab is not offered on Graham.
Attached storage systems[edit]
| Home space | |
| Scratch space 3.6PB total volume Parallel high-performance filesystem |
|
| Project space External persistent storage |
|
High-performance interconnect[edit]
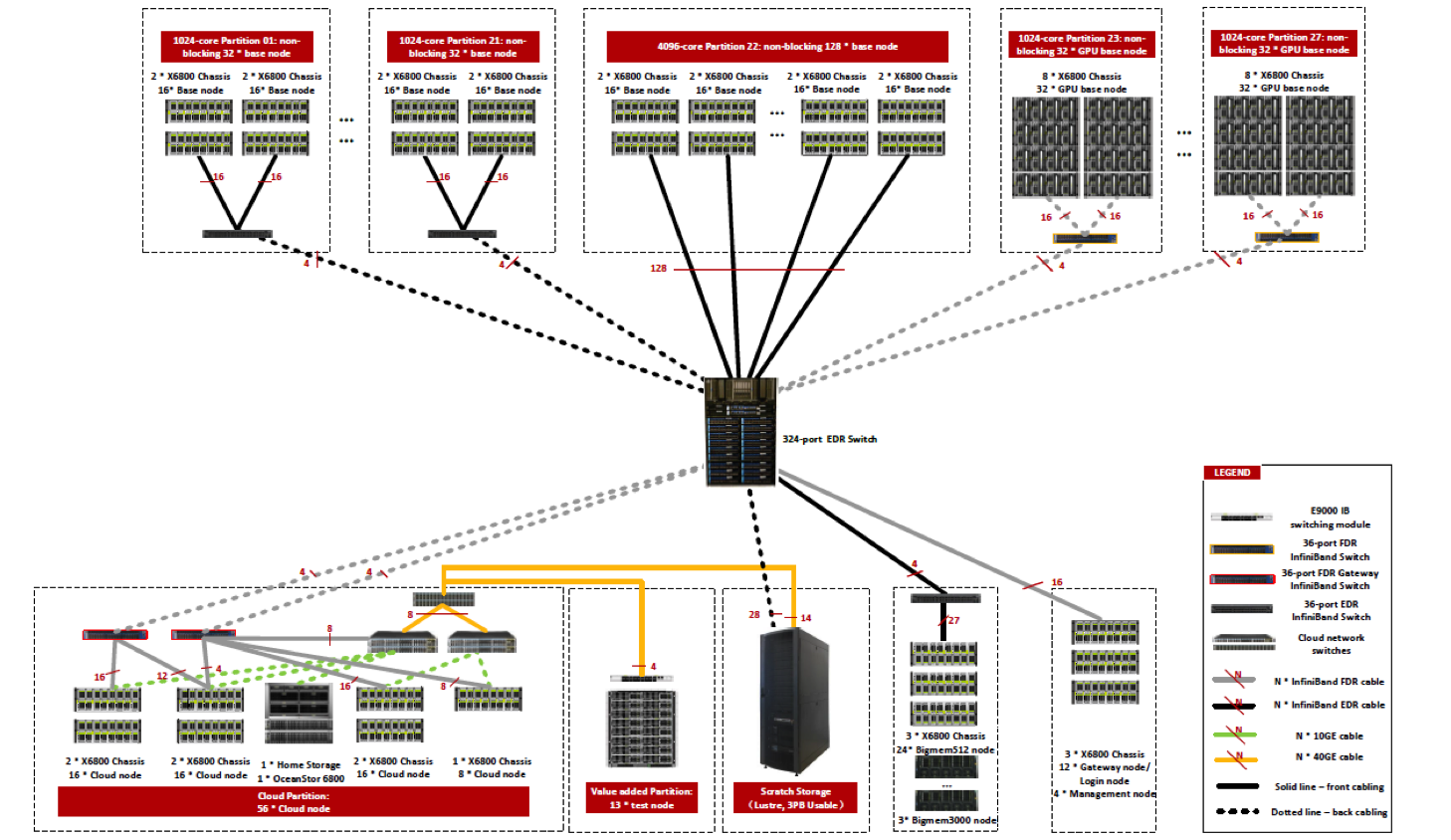
Mellanox FDR (56Gb/s) and EDR (100Gb/s) InfiniBand interconnect. FDR is used for GPU and cloud nodes, EDR for other node types. A central 324-port director switch aggregates connections from islands of 1024 cores each for CPU and GPU nodes. The 56 cloud nodes are a variation on CPU nodes, and are on a single larger island sharing 8 FDR uplinks to the director switch.
A low-latency high-bandwidth Infiniband fabric connects all nodes and scratch storage.
Nodes configurable for cloud provisioning also have a 10Gb/s Ethernet network, with 40Gb/s uplinks to scratch storage.
The design of Graham is to support multiple simultaneous parallel jobs of up to 1024 cores in a fully non-blocking manner.
For larger jobs the interconnect has a 8:1 blocking factor, i.e., even for jobs running on multiple islands the Graham system provides a high-performance interconnect.
Graham high performance interconnect diagram
{kind=link}
Visualization on Graham[edit]
Graham has dedicated visualization nodes available at gra-vdi.computecanada.ca that allow only VNC connections. For instruction on how to use them, see the VNC page. We are working on making the complete graham software stack available on the visualization nodes.
Node types and characteristics[edit]
A total of 36,160 cores and 320 GPU devices, spread across 1,127 nodes of different types.
Processor type: All nodes except bigmem3000 have Intel E5-2683 V4 CPUs, running at 2.1 GHz
GPU type: P100 12g
| count | Node type | cores | available memory | hardware detail |
|---|---|---|---|---|
| 884 | base "128G" | 32 | 125G or 128000M | two Intel E5-2683 v4 "Broadwell" at 2.1Ghz; 960GB SATA SSD |
| 24 | large "512G" | 32 | 502G or 514500M | (same as base nodes) |
| 56 | large/cloud | 32 | 250G or 256500M | (same as base nodes) may be reserved for cloud use |
| 3 | bigmem3000 "3T" | 64 | 3022G or 3095000M | like base nodes but four E7-4850 v4 "Broadwell" CPUs at 2.1Ghz |
| 160 | GPU | 32 | 124G or 127518M | like base nodes but also two NVIDIA P100 Pascal GPUs (12GB HBM2 memory, 1.6TB NVMe SSD |
Best practice for local on-node storage is to use the temporary directory generated by Slurm, $SLURM_TMPDIR. Note that this directory and its contents will disappear upon job completion.
Note that the amount of available memory is less than the "round number" suggested by hardware configuration. For instance, "base" nodes do have 128 GiB of RAM, but some of it is permanently occupied by the kernel and OS. To avoid wasting time by swapping/paging, the scheduler will never allocate jobs whose memory requirements exceed the specified amount of "available" memory. Please also note that the memory allocated to the job must be sufficient for IO buffering performed by the kernel and filesystem - this means that an IO-intensive job will often benefit from requesting somewhat more memory than the aggregate size of processes.
Volta GPU nodes on Graham[edit]
In the Winter of 2019 seven new Volta GPU nodes have been added.
The node specifications are as follows:
gra[1148-1153]
- 2 Sockets
- 14 CoresPerSocket
- 192 GB
- 3.6 TB NVMe /local disk
- 8 x V100 (16 GB) GPUs (4 per socket)
gra1147
- Same as above, except for 6 x V100 (16 GB) GPUs (3 per socket).
The nodes are still in testing and access can be granted to Ontario researchers by request.
Here is an example job script to submit a job to one of the nodes (with 8 GPUs). The module load command will ensure that modules compiled for Skylake architecture will be used. Replace nvidia-smi with the command you want to run.
Important: You should scale the number of CPUs requested, keeping the ratio of CPUs to GPUs at 3.5 or less. For example, if you want to run a job using 4 GPUs, you should request at most 14 CPU cores. For a job with 1 GPU, you should request at most 3 CPU cores. As the nodes are in testing, for now users are allowed to run a few short test jobs (shorter than 1 hour) that break this rule to see how your code performs.
#!/bin/bash
#SBATCH --account=ctb-ontario
#SBATCH --partition=c-ontario
#SBATCH --nodes=1
#SBATCH --gres=gpu:v100:8
#SBATCH --exclusive
#SBATCH --cpus-per-task=28
#SBATCH --mem=150G
#SBATCH --time=3-00:00
module load arch/avx512 StdEnv/2018.3
nvidia-smi
The graham Volta nodes have a fast local disk, which should be used for jobs if the amount of I/O performed by your job is significant. Inside the job, the location of the temporary directory on fast local disk is specified by the environment variable $SLURM_TMPDIR. You can copy your input files there at the start of your job script before you run your program and your output files out at the end of your job script. All the files in $SLURM_TMPDIR will be removed once the job ends, so you do not have to clean up that directory yourself. You can even create Python virtual environments in this temporary space for greater efficiency. Please see Python#Creating_virtual_environments_inside_of_your_jobs for information on how to that.