Allocations and compute scheduling
Parent page: Job scheduling policies
What is an allocation?
An allocation is an amount of resources that a research group can target for use for a period of time, usually a year. This amount is either a maximum amount, as is the case for storage, or an average amount of usage over the period, as is the case for shared resources like computation cores.
Allocations are usually made in terms of core years, GPU years, or storage space. Storage allocations are the most straightforward to understand: research groups will get a maximum amount of storage that they can use exclusively throughout the allocation period. Core year and GPU year allocations are more difficult to understand because these allocations are meant to capture average use throughout the allocation period---typically meant to be a year---and this use will occur across a set of resources shared with other research groups.
The time period of an allocation when it is granted is a reference value, used for the calculation of the average which is applied to the actual period during which the resources are available. This means that if the allocation period was a year and the clusters were down for a week of maintenance, a research group would not be entitled to an additional week of resource usage. Equally so, if the allocation period were to be extended by a month, research groups affected by such a change would not see their resource access diminish during this month.
It should be noted that in the case of core year and GPU year allocations, both of which target resource usage averages over time on shared resources, a research group is more likely to hit (or exceed) its target(s) if the resources are used evenly over the allocation period than if the resources are used in bursts or if use is put off until later in the allocation period.
Viewing group usage of compute resources

Information on the usage of compute resources by your groups can be found by logging into the CCDB and navigating to My Account > View Group Usage.

CPU and GPU core year values are calculated based on the quantity of the resources allocated to jobs on the clusters. It is important to note that the values summarized in these pages do not represent core-equivalent measures such that, in the case of large memory jobs, the usage values will not match the cluster scheduler’s representation of the account usage.
The first tag bar offers these options:
- By Compute Resource: cluster on which jobs are submitted;
- By Resource Allocation Project: projects to which jobs are submitted;
- By Submitter: user that submits the jobs;
- Storage usage is discussed in Storage and file management.
Usage by compute resource
This view shows the usage of compute resources per cluster used by groups owned by you or of which you are a member for the current allocation year starting April 1st. The tables contain the total usage to date as well as the projected usage to the end of the current allocation period.

From the Extra Info column of the usage table Show monthly usage can be clicked to display a further breakdown of the usage by month for the specific cluster row in the table. By clicking Show submitter usage, a similar breakdown is displayed for the specific users submitting the jobs on the cluster.
Usage by resource allocation project

Under this tab, a third tag bar displays the RAPIs (Resource Allocation Project Identifiers) for the selected allocation year. The tables contain detailed information for each allocation project and the resources used by the projects on all of the clusters. The top of the page summarizes information such as the account name (e.g. def-, rrg- or rpp-*, etc), the project title and ownership, as well as allocation and usage summaries.
Usage by submitter

Usage can also be displayed grouped by the users that submitted jobs from within the resource allocation projects (group accounts). The view shows the usage for each user aggregated across systems.
Selecting from the list of users will display that user’s usage broken down by cluster. Like the group summaries, these user summaries can then be broken down monthly by clicking the Show monthly usage link of the Extra Info column of the CPU/GPU Usage (in core/GPU] years) table for the specific Resource row.
What happens if my group overuses my CPU or GPU allocation?
Nothing bad. Your CPU or GPU allocation is a target level, i.e., a target number of CPUs or GPUs. If you have jobs waiting to run, and competing demand is low enough, then the scheduler may allow more of your jobs to run than your target level. The only consequence of this is that succeeding jobs of yours may have lower priority for a time while the scheduler prioritizes other groups which were below their target. You are not prevented from submitting or running new jobs, and the time-average of your usage should still be close to your target, that is, your allocation.
It is even possible that you could end a month or even a year having run more work than your allocation would seem to allow, although this is unlikely given the demand on our resources.
How does scheduling work?
Compute-related resources granted by core-year and GPU-year allocations require research groups to submit what are referred to as “jobs” to a “scheduler”. A job is a combination of a computer program (an application) and a list of resources that the application is expected to use. The scheduler is a program that calculates the priority of each job submitted and provides the needed resources based on the priority of each job and the available resources.
The scheduler uses prioritization algorithms to meet the allocation targets of all groups and it is based on a research group’s recent usage of the system as compared to their allocated usage on that system. The past of the allocation period is taken into account but the most weight is put on recent usage (or non-usage). The point of this is to allow a research group that matches their actual usage with their allocated amounts to operate roughly continuously at that level. This smooths resource usage over time across all groups and resources, allowing for it to be theoretically possible for all research groups to hit their allocation targets.
How does resource use affect priority?
The overarching principle governing the calculation of priority on Compute Canada's new national clusters is that compute-based jobs are considered in the calculation based on the resources that others are prevented from using and not on the resources actually used.
The most common example of unused cores contributing to a priority calculation occurs when a submitted job requests multiple cores but uses fewer cores than requested when run. The usage that will affect the priority of future jobs is the number of cores requested, not the number of cores the application actually used. This is because the unused cores were unavailable to others to use during the job.
Another common case is when a job requests memory beyond what is associated with the cores requested. If a cluster that has 4GB of memory associated with each core receives a job request for only a single core but 8GB of memory, then the job will be deemed to have used two cores. This is because other researchers were effectively prevented from using the second core because there was no memory available for it.
The details of how resources are accounted for require a sound understanding of the core equivalent concept, which is discussed below.[1]
What is a core equivalent and how is it used by the scheduler?
A core equivalent is a bundle made up of a single core and some amount of associated memory. In other words, a core equivalent is a core plus the amount of memory considered to be associated with each core on a given system.

Cedar and Graham are considered to provide 4GB per core, since this corresponds to the most common node type in those clusters, making a core equivalent on these systems a core-memory bundle of 4GB per core. Niagara is considered to provide 4.8GB of memory per core, making a core equivalent on it a core-memory bundle of 4.8GB per core. Jobs are charged in terms of core equivalent usage at the rate of 4 or 4.8 GB per core, as explained above. See Figure 1.
Allocation target tracking is straightforward when requests to use resources on the clusters are made entirely of core and memory amounts that can be portioned only into complete equivalent cores. Things become more complicated when jobs request portions of a core equivalent because it is possible to have many points counted against a research group’s allocation, even when they are using only portions of core equivalents. In practice, the method used by Compute Canada to account for system usage solves problems about fairness and perceptions of fairness but unfortunately the method is not initially intuitive.
Research groups are charged for the maximum number of core equivalents they take from the resources. Assuming a core equivalent of 1 core and 4GB of memory:
- Research groups using more cores than memory (above the 1 core/4GB memory ratio), will be charged by cores. For example, a research group requesting two cores and 2GB per core for a total of 4 GB of memory. The request requires 2 core equivalents worth of cores but only one bundle for memory. This job request will be counted as 2 core equivalents when priority is calculated. See Figure 2.
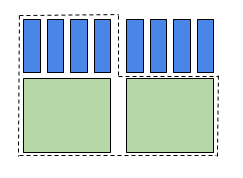 Figure 2 - Two core equivalents.
Figure 2 - Two core equivalents.

- Research groups using more memory than the 1 core/4GB ratio will be charged by memory. For example, a research group requests two cores and 5GB per core for a total of 10 GB of memory. The request requires 2.5 core equivalents worth of memory, but only two bundles for cores. This job request will be counted as 2.5 core equivalents when priority is calculated. See Figure 3.
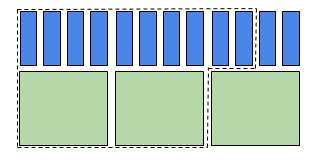 Figure 3 - 2.5 core equivalents.
Figure 3 - 2.5 core equivalents.

What is a GPU equivalent and how is it used by the scheduler?
Use of GPUs and their associated resources follow the same principles as already described for core equivalents. The complication is that it is important to separate allocation targets for GPU-based research from allocation targets for non-GPU-based research to ensure that we can meet the allocation targets in each case. If these cases were not separated, then it would be possible for a non-GPU-based researcher to use their allocation targets in the GPU-based research pool, adding load that would effectively block GPU-based researchers from meeting their allocation targets and vice versa.
Given this separation, a distinction must be made between core equivalents and GPU equivalents. Core equivalents are as described above. The GPU-core-memory bundles that make up a GPU equivalent are similar to core-memory bundles except that a GPU is added to the bundle alongside multiple cores and memory. This means that accounting for GPU-based allocation targets must include the GPU. Similar to how the points system was used above when considering resource use as an expression of the concept of core equivalence, we will use a similar point system here as an expression of GPU equivalence.
Research groups are charged for the maximum number of GPU-core-memory bundles they use. Assuming a core-memory bundle of 1 GPU, 6 cores, and 32GB of memory:

- Research groups using more GPUs than cores or memory per GPU-core-memory bundle will be charged by GPU. For example, a research group requests 2 GPUs, 6 cores, and 32GB of memory. The request is for 2 GPU-core-memory bundles worth of GPUs but only one bundle for memory and cores. This job request will be counted as 2 GPU equivalents when the research group’s priority is calculated.

- Research groups using more cores than GPUs or memory per GPU-core-memory bundle will be charged by core. For example, a researcher requests 1 GPU, 9 cores, and 32GB of memory. The request is for 1.5 GPU-core-memory bundles worth of cores, but only one bundle for GPUs and memory. This job request will be counted as 1.5 GPU equivalents when the research group’s priority is calculated.
.png)
- Research groups using more memory than GPUs or cores per GPU-core-memory bundle will be charged by memory. For example, a researcher requests 1 GPU, 6 cores, and 48GB of memory. The request is for 1.5 GPU-core-memory bundles worth of memory but only one bundle for GPUs and cores. This job request will be counted as 1.5 GPU equivalents when the research group’s priority is calculated.
.png)
Ratios: GPU / CPU Cores / System-memory
Compute Canada systems have the following GPU-core-memory bundle characteristics:
- Béluga:
- V100/16GB nodes: 1 GPU / 10 cores / 47000 MB
- Cedar:
- P100/12GB nodes: 1 GPU / 6 cores / 32000 MB
- P100/16GB nodes: 1 GPU / 6 cores / 64000 MB
- V100/32GB nodes: 1 GPU / 8 cores / 48000 MB
- Graham:
- P100/12GB nodes: 1 GPU / 16 cores / 64000 MB
- V100/16GB nodes: 1 GPU / 3.5 cores / 22500 MB
- V100/32GB nodes: 1 GPU / 5 cores / 48000 MB
- T4/16GB nodes: 1 GPU / {4,11} cores / 49000 MB
- Narval:
- A100/40GB nodes: 1 GPU / 12 cores / 127000 MB
- ↑ Further details about how priority is calculated are beyond the scope of this document. Additional documentation is in preparation. We also suggest that a training course might be valuable for anyone wishing to know more.