Allocations and compute scheduling/fr: Difference between revisions
(Created page with "=Consulter l'utilisation des ressources dans le portail=") |
No edit summary |
||
| Line 378: | Line 378: | ||
<br clear=all> | <br clear=all> | ||
=Visionner l'utilisation des ressources dans CCDB= | |||
=Visionner | |||
[[File:Select view group usage fr edit.png|thumb|Onglet <i>Mon compte</i>, option <i>Utilisation par le groupe</i>]] | [[File:Select view group usage fr edit.png|thumb|Onglet <i>Mon compte</i>, option <i>Utilisation par le groupe</i>]] | ||
Revision as of 21:08, 11 November 2024
Page enfant de Politique d'ordonnancement des tâches
Allocations pour le calcul haute performance
Une allocation est l’attribution d’une quantité de ressources à un groupe de recherche pour une période donnée, habituellement un an. Il s'agit soit d'un maximum comme dans le cas du stockage, soit d'une moyenne d'utilisation sur une période donnée comme c'est le cas pour les ressources partagées que sont les cœurs de calcul.
L’allocation des ressources de stockage attribue un maximum déterminé d’espace réservé à l’usage exclusif d’un groupe de recherche. Pour sa part, l’allocation des ressources partagées que sont les cœurs-année et les GPU-année est plus complexe puisque ces ressources sont partagées par l’ensemble des groupes et que l’allocation tient compte de l’utilisation moyenne de chaque groupe.
La durée de l’allocation est une valeur de référence utilisée pour calculer la moyenne de la consommation des ressources au cours de la période pendant laquelle celles-ci sont disponibles. Par exemple, si les grappes ne sont pas disponibles pour une semaine dû à des opérations de maintenance, les groupes de recherche touchés n’obtiennent pas une semaine additionnelle en compensation à la fin de la période. De la même manière, si la période d’allocation est allongée, les groupes n’y perdent pas en utilisation.
Notons qu’une allocation de cœurs-année et de GPU-année en ressources partagées considère la moyenne d’utilisation cible dans le temps; un groupe est donc plus susceptible d’atteindre et même de dépasser ses cibles en utilisant ses ressources de façon régulière sur la période qu’en soumettant des tâches en rafale (burst) ou en les reportant à plus tard.
De l'allocation à l'ordonnancement par priorité
Les ressources de calcul par cœurs-année et par GPU-année reçoivent des tâches qui sont immédiatement prises en charge par l’ordonnanceur. Rappelons qu’une tâche se compose d’une application logicielle et de la liste des ressources pour l’exécuter. L’ordonnanceur est aussi une application logicielle dont le rôle est de calculer la priorité de chaque tâche et de lui attribuer les ressources nécessaires selon leur disponibilité et en accord avec les règles de priorisation.
À l’aide d’algorithmes spécialisés, l’ordonnanceur tient compte des cibles de chaque groupe et compare la consommation récente du groupe à l’utilisation qui lui était allouée. Un des facteurs déterminants est la consommation à l’intérieur de la période. Le facteur qui possède cependant le plus de poids est la consommation (ou la non-consommation) récente, ceci en vue d’offrir une opération plus stable aux groupes dont l’utilisation réelle se rapproche des ressources qui leur étaient allouées. Cette façon de procéder assure une meilleure répartition du parc de ressources pour l’ensemble des groupes et fait en sorte qu’il est théoriquement possible pour tous les groupes d’atteindre leurs cibles.
Conséquences d'une surutilisation d'une allocation CPU ou GPU
Si vous avez des tâches en attente et qu’à ce moment la demande en ressources de calcul est basse, l’ordonnanceur pourrait faire exécuter vos tâches même si vous dépassez la quantité cible de votre allocation. Tout ce qui peut se produire alors serait que les prochaines tâches que vous soumettrez se voient attribuer un plus bas niveau de priorité que celles soumises par des groupes qui n’ont pas encore atteint leur niveau cible d’utilisation. Aucune tâche soumise à l’ordonnanceur n’est refusée en raison d’une surutilisation de ressources et votre utilisation moyenne de ressources sur la période d’allocation devrait se situer proche de la cible qui vous a été allouée.
Il se pourrait qu’au cours d’un mois ou d’une année vous puissiez accomplir plus de travail que votre allocation ne semblerait le permettre, mais ce scénario est peu probable puisque la demande est plus élevée que la quantité de ressources dont nous disposons.
Unités GPU de référence (UGR)
La performance des GPU a considérablement augmenté ces dernières années et continue sa progression. Par le passé et jusqu'au concours de 2023, nous considérions tous les GPU comme étant équivalents les uns aux autres. Ceci posait des problèmes à la fois dans le processus d'attribution et lors de l'exécution des tâches. Pour contrer ceci, nous avons créé pour l'année 2024 l'unité GPU de référence (UGR) qui permet de classer tous les modèles de GPU en production. Pour la période d'allocation de 2025-2026, nous devrons tenir compte de la technologie des GPU multi-instances qui rend la situation un peu plus complexe.
Parce qu'environ la moitié des tâches utilisent principalement des opérations à virgule flottante simple précision (FP32), que les autres utilisent des opérations à virgule flottante demi-précision (FP16), et que la plupart des utilisateurs sont limités par la quantité de mémoire des GPU, nous classons les modèles de GPU selon les critères d'évaluation avec leur poids correspondant :
| Critère d'évaluation | Poids |
|---|---|
| score FP32 (matrices denses sur les cœurs GPU réguliers) | 40% |
| FP16 score (matrices denses sur les cœurs Tensor) | 40% |
| GPU memory score | 20% |
Nous utilisons le GPU A100-40gb de NVidia comme modèle de référence, auquel nous assignons la valeur UGR de 4 (pour des raisons historiques). Sa mémoire et ses performances FP32 et FP16 sont fixées à 1.0. En multipliant les pourcentages dans le tableau précédent par 4, nous obtenons les coefficients et les valeurs UGR pour les autres modèles.
| Score FP32 | Score FP16 | Score mémoire | Score combiné | Disponible | Alloué par concours | ||
|---|---|---|---|---|---|---|---|
| COEFFICIENT | 1.6 | 1.6 | 0.8 | (UGR) | Présentement | Pour 2025 | Concours de 2025 |
| H100-80gb | 3.44 | 3.17 | 2.0 | 12.2 | non | oui | oui |
| A100-80gb | 1.00 | 1.00 | 2.0 | 4.8 | non | ? | non |
| A100-40gb | 1.00 | 1.00 | 1.0 | 4.0 | Yes | Yes | Yes |
| V100-32gb | 0.81 | 0.40 | 0.8 | 2.6 | oui | ? | non |
| V100-16gb | 0.81 | 0.40 | 0.4 | 2.2 | oui | ? | non |
| T4-16gb | 0.42 | 0.21 | 0.4 | 1.3 | oui | ? | non |
| P100-16gb | 0.48 | 0.03 | 0.4 | 1.1 | oui | non | non |
| P100-12gb | 0.48 | 0.03 | 0.3 | 1.0 | oui | non | non |
Le renouvellement de l'infrastructure en 2025 permettra de planifier une fraction d'un GPU à l'aide de la technologie GPU multi-instances. Différents travaux, appartenant potentiellement à différents utilisateurs, pourront s'exécuter sur le même GPU en même temps. Selon la terminologie de NVidia, une fraction d'un GPU allouée à un seul travail est appelée une instance GPU, (parfois instance MIG).
Le tableau suivant montre les modèles de GPU ou instances que vous pouvez sélectionner sur le formulaire dans CCDB pour votre demande d'allocation pour la période 2025-2026. Les valeurs UGR des instances sont estimées à partir des valeurs de performance d'un GPU entier et de la fraction du GPU qu'occupe l'instance.
| Modèle / Instance | Fraction du GPU | UGR |
|---|---|---|
| A100-40gb | GPU entier ⇒ 100% | 4.0 |
| A100-3g.20gb | max(3g/7g, 20GB/40GB) ⇒ 50% | 2.0 |
| A100-4g.20gb | max(4g/7g, 20GB/40GB) ⇒ 57% | 2.3 |
| H100-80gb | GPU entier ⇒ 100% | 12.2 |
| H100-1g.10gb | max(1g/7g, 40GB/80GB) ⇒ 14% | 1.7 |
| H100-2g.20gb | max(2g/7g, 40GB/80GB) ⇒ 28% | 3.5 |
| H100-3g.40gb | max(3g/7g, 40GB/80GB) ⇒ 50% | 6.1 |
| H100-4g.40gb | max(4g/7g, 40GB/80GB) ⇒ 57% | 7.0 |
Remarque : Une instance GPU ayant le profil 1g vaut un septième (1/7) d'un GPU A100 ou H100. Le profil 3g tient compte de la quantité de mémoire additionnelle par g.
Choisir les modèles de GPU pour votre projet
Les scores relatifs du précédent tableau devraient vous aider à sélectionner les modèles les plus convenables. Les exemples suivants présentent des cas extrêmes.
- Si vos applications font surtout des opérations FP32, le modèle A100-40gb devrait être deux fois plus rapide que le P100-12gb, mais l'utilisation des ressources sera considérée comme étant quatre fois plus grande. En conséquence, pour le même nombre d'UGR, le modèle P100-12gb devrait vous permettre d'exécuter deux fois plus de calculs.
- Si vos applications font surtout des opérations FP16 (ce qui est le cas en intelligence artificielle et avec les opérations à précision mixte ou utilisant d'autres formats à virgule flottante), l'utilisation d'un A100-40gb sera calculée comme utilisant quatre fois les ressources d'un P100-12gb, mais pourra faire ~30 fois plus de calculs dans la même période, ce qui vous permettrait d'exécuter ~7.5 fois plus de calculs.
Constance des allocations en UGR
- Dans le cadre du concours pour l'allocation de ressources, toute demande de GPU doit spécifier le modèle de GPU préféré pour le projet. Ensuite, dans le formulaire CCDB, la quantité d'unités GPU de référence (UGR) sera automatiquement calculée à partir de la quantité demandée de GPU-année par année de projet.
- Par exemple, si vous sélectionnez la ressource narval-gpu et demandez 13 GPU-année du modèle A100-40gb, la quantité correspondante en UGR serait de 13 * 4,0 = 52. Le comité d’allocation des ressources attribuerait alors jusqu'à 52 UGR en fonction du score de la proposition. Si votre allocation doit être déplacée vers une autre grappe, le comité attribuera des GPU-année à cette autre ressource tout en conservant la même quantité en UGR.
Effet détaillé de l'utilisation des ressources sur la priorité
Le principe gouverneur dans notre façon de déterminer la priorité des tâches de calcul se base sur les ressources qu’une tâche rend non disponibles aux autres utilisateurs plutôt que sur les ressources effectivement utilisées.
Le cas de cœurs non utilisés qui influent sur le calcul des priorités se produit souvent lorsqu’une tâche est soumise en demandant plusieurs cœurs, mais n’en consomme effectivement qu’une partie à l’exécution. C’est le nombre de cœurs demandés par une tâche qui a une incidence sur la priorisation des prochaines tâches puisque la tâche bloque les cœurs non utilisés pendant son exécution.
Un autre cas fréquent de cœurs non utilisés se pose lorsqu’une tâche exige plus de mémoire que celle demandée pour un cœur. Sur une grappe où chaque cœur serait doté de 4Go de mémoire, une tâche qui demanderait un seul cœur et 8Go de mémoire bloquerait donc 2 cœurs et le deuxième cœur ne serait pas disponible pour les tâches des autres groupes de recherche
Équivalents-cœurs utilisés par l'ordonnanceur
Un équivalent-cœur se compose d’un cœur simple et d’une certaine quantité de mémoire; pour le nommer, nous utilisons le terme bundle. En plus du cœur, le bundle contient aussi la mémoire considérée comme étant associée à ce cœur.

Cedar et Graham offrent surtout des cœurs de 4Go et dans leur cas, l’équivalent-cœur est un bundle de 4 Go (voir Figure 1). Pour sa part, Niagara offre surtout des cœurs de 4.8Go, donc des bundles de 4.8Go. L’utilisation des ressources par une tâche est comptabilisée à raison de 4Go ou 4.8Go par cœur, comme mentionné ci-dessus.
Le suivi des cibles s’avère relativement simple quand les ressources demandées sont des cœurs et des quantités de mémoire qui correspondent à un équivalent-cœur entier, plutôt qu’à une portion d’équivalent-cœur. Les choses se compliquent parce que l’utilisation de portions d’équivalents-cœur risque d’augmenter le pointage servant au calcul de la juste part du groupe de recherche. En pratique, la méthode appliquée résout le problème d'équité ou de perception d'équité, mais cette méthode n’est pas intuitive au début.
Dans les exemples qui suivent, la mémoire est de 4Go.
Comptabilisation par équivalents-cœur
Examinons le cas où nous avons un bundle composé de 1 cœur et 4Go de mémoire.
- Les cœurs sont comptabilisés si un groupe utilise plus de cœurs que de mémoire, c’est-à-dire plus que le ratio 1cœur/4Go.
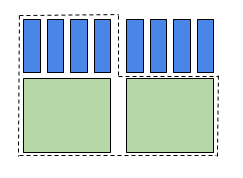 Figure 2 – Deux équivalents-cœurs
Figure 2 – Deux équivalents-cœurs- Dans la figure 2, on demande 2 cœurs et 2Go par cœur pour une mémoire totale de 4Go; la tâche exige 2 équivalents-cœur pour les cœurs, mais un seul bundle pour la mémoire. Pour calculer la priorité, l’ordonnanceur évalue la demande à 2 équivalents-cœurs.
- Dans la figure 2, on demande 2 cœurs et 2Go par cœur pour une mémoire totale de 4Go; la tâche exige 2 équivalents-cœur pour les cœurs, mais un seul bundle pour la mémoire. Pour calculer la priorité, l’ordonnanceur évalue la demande à 2 équivalents-cœurs.

- La mémoire est comptabilisée si un groupe utilise plus de mémoire que le ratio de 1 cœur/4Go.
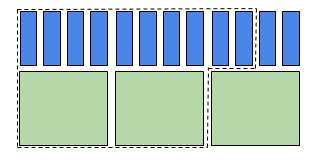 Figure 3 – 2.5 équivalents-cœur
Figure 3 – 2.5 équivalents-cœur- Dans la figure 3, on demande 2 cœurs et 5Go par cœur pour une mémoire totale de 10Go; la tâche exige 2.5 bundles pour les cœurs. Pour calculer la priorité, l’ordonnanceur évalue la demande à 2.5 équivalents-cœurs.
- Dans la figure 3, on demande 2 cœurs et 5Go par cœur pour une mémoire totale de 10Go; la tâche exige 2.5 bundles pour les cœurs. Pour calculer la priorité, l’ordonnanceur évalue la demande à 2.5 équivalents-cœurs.

Équivalents-UGR utilisés par l'ordonnanceur
L’utilisation des GPU et leurs ressources associées suit les mêmes principes que ceux décrits pour les équivalents-coeurs, sauf qu’une UGR est ajoutée au bundle avec de la mémoire et plusieurs cœurs. Ceci signifie que la comptabilisation de l’utilisation de la cible pour l’allocation de GPU doit inclure l’UGR. Tout comme le système de points utilisé dans l’expression de l’utilisation de la ressource en équivalents-cœurs, nous utilisons aussi un système de points pour les équivalents-UGR.
Le calcul de priorité se fait en fonction du nombre maximum de bundles UGR-coeurs-mémoire demandés. Examinons le cas où nous avons un bundle de 1 UGR, 3 cœurs et 4Go de mémoire.

- Les UGR sont comptabilisés si un groupe utilise plus de UGR que de cœurs OU de mémoire par bundle. Prenons l'exemple d'un usager demandant 2 GPU (de 1 UGR chacun), 3 cœurs et 4Go de mémoire. La tâche exige donc l'équivalent de 2 bundles pour les GPU, mais un seul pour les cœurs et la mémoire. Pour calculer la priorité, l’ordonnanceur évalue la demande à 2 équivalents-UGR.
.png)
- Les cœurs sont comptabilisés si un groupe utilise plus de cœurs que de UGR OU plus de mémoire par bundle avec GPU. Dans la figure 6, on demande 1 GPU de 1 UGR, 5 cœurs et 5Go; la requête exige donc 1.66 bundles avec GPU pour les cœurs, mais un seul bundle pour le GPU et 1.25 bundle pour la mémoire. Pour calculer la priorité, l’ordonnanceur évalue donc la demande à 1.66 équivalents-UGR.
.png)
- La mémoire est comptabilisée si un groupe utilise plus de mémoire que de UGR OU de cœurs par bundle avec GPU. Dans la figure 7, on demande 1 GPU de 1 UGR, 2 cœurs et 6Go; la requête exige donc 1.5 bundle avec GPU pour la mémoire, mais un seul bundle pour les GPU et 0.66 pour les cœurs. Pour calculer la priorité, l’ordonnanceur évalue la demande à 1.5 équivalents-GPU.
.png)
- Sur la même grappe fictive, un bundle comprenant un GPU V100-32gb, 7.8 cœurs et 10.4 Go de mémoire-vive vaudrait 2.6 équivalents-UGR :

- Sur la même grappe fictive, un bundle comprenant un GPU A100-40gb, 12 cœurs et 16 Go de mémoire-vive vaudrait 4.0 équivalents-UGR :

Ratios dans les bundles
Les différents bundles UGR-coeur-mémoire et GPU-coeur-mémoire des systèmes de l'Alliance ont les caractéristiques suivantes :
| Grappe | Modèle ou instance | UGR par GPU | Bundle par UGR | Bundle par GPU |
|---|---|---|---|---|
| Béluga* | V100-16gb | 2.2 | 4.5 cœurs, 21 Go | 10 cœurs, 46.5 Go |
| Cedar* | P100-12gb | 1.0 | 3.1 cœurs, 25 Go | 3.1 cœurs, 25 Go |
| P100-16gb | 1.1 | 3.4 cœurs, 27 Go | ||
| V100-32gb | 2.6 | 8.0 cœurs, 65 Go | ||
| Fir | H100-80gb | 12.2 | 0.98 cœur, 20.5 Go | 12 cœurs, 250 Go |
| H100-1g.10gb | 1.7 | 1.6 cœurs, 34.8 Go | ||
| H100-2g.20gb | 3.5 | 3.4 cœurs, 71.7 Go | ||
| H100-3g.40gb | 6.1 | 6 cœurs, 125 Go | ||
| H100-4g.40gb | 7.0 | 6.9 cœurs, 143 Go | ||
| Graham* | P100-12gb | 1.0 | 9.7 cœurs, 43 Go | 9.7 cœurs, 43 Go |
| T4-16gb | 1.3 | 12.6 cœurs, 56 Go | ||
| V100-16gb | 2.2 | 21.3 cœurs, 95 Go | ||
| V100-32gb | 2.6 | 25.2 cœurs, 112 Go | ||
| A100-80gb | 4.8 | 46.6 cœurs, 206 Go | ||
| Graham II | H100-80gb | 12.2 | 1.3 cœurs, 15.3 Go | 16 cœurs, 187 Go |
| H100-1g.10gb | 1.7 | 2.2 cœurs, 26 Go | ||
| H100-2g.20gb | 3.5 | 4.5 cœurs, 53.5 Go | ||
| H100-3g.40gb | 6.1 | 8 cœurs, 93.5 Go | ||
| H100-4g.40gb | 7.0 | 9.1 cœurs, 107 Go | ||
| Narval | A100-40gb | 4.0 | 3.0 cœurs, 31 Go | 12 cœurs, 124.5 Go |
| A100-3g.20gb | 2.0 | 6 cœurs, 62.3 Go | ||
| A100-4g.20gb | 2.3 | 6.9 cœurs, 71.5 Go | ||
| Rorqual | H100-80gb | 12.2 | 1.3 cœurs, 10.2 Go | 16 cœurs, 124.5 Go |
| H100-1g.10gb | 1.7 | 2.2 cœurs, 17.4 Go | ||
| H100-2g.20gb | 3.5 | 4.5 cœurs, 35.8 Go | ||
| H100-3g.40gb | 6.1 | 8 cœurs, 62.3 Go | ||
| H100-4g.40gb | 7.0 | 9.1 cœurs, 71.5 Go |
(*) Toutes les ressources GPU de cette grappe ne sont pas allouées par la voie du concours annuel d'allocation des ressources.
Remarque : Si l'ordonnanceur établit la priorité sur la base de l'utilisation calculée avec les bundles, une demande de plusieurs GPU sur un même nœud doit aussi tenir compte des ratios physiques.
Consulter l'utilisation des ressources dans le portail

portal.alliancecan.ca/slurm provides an interface for exploring time-series data about jobs on our national clusters. The page contains a figure that can display several usage metrics. When you first log in to the site, the figure will display CPU days on the Cedar cluster for you across all project accounts that you have access to. If you have no usage on Cedar, the figure will contain the text No Data or usage too small to have a meaningful plot. The data appearing in the figure can be modified by control panels along the left margin of the page. There are three panels:
- Select system and dates
- Parameters
- SLURM account
Displaying a specified account

If you have access to more than one Slurm account, the Select user’s account pull-down menu of the SLURM account panel lets you select which project account will be displayed in the figure window. If the Select user’s account is left empty the figure will display all of your usage across accounts on the specified cluster during the selected time period. The Select user’s account pull-down menu is populated by a list of all the accounts that have job records on the selected cluster during the selected time interval. Other accounts that you have access to but do not have usage on the selected cluster during the selected time interval will also appear in the pull-down menu but will be grayed out and not selectable as they would not generate a figure. When you select a single project account the figure is updated and the summary panel titled Allocation Information is populated with details of the project account. The height of each bar in the histogram figure corresponds to the metric for that day (e.g. CPU-equivalent days) across all users in the account on the system. The top eight users are displayed in unique colors stacked on top of the summed metric for all other users in gray. You can navigate the figure using Plotly tools (zoom, pan, etc.) whose icons appear at the top-right when you hover your mouse over the figure window. You can also use the legend on the right-hand side to manipulate the figure. Single-clicking an item will toggle the item's presence in the figure, and double-clicking the item will toggle off or on all the other items in the figure.
Displaying the allocation target and queued resources

When a single account has been selected for display, the Allocation target is shown as a horizontal red line. It can be turned off or on with the Display allocation target by default item in the Parameters panel, or by clicking on Allocation target in the legend to the right of the figure.
You can toggle the display of the Queued jobs metric, which presents a sum of all resources in pending jobs at each time point, by clicking on the words Queued jobs in the legend to the right of the figure.
Selecting a specific cluster and time interval

The figure shows your usage for a single cluster over a specified time interval. The System pull-down menu contains entries for each of the currently active national clusters that use Slurm as a scheduler. You can use the "Start date (incl.)" and "End date (incl.)" fields in the "Select system and dates" panel to change the time interval displayed in the figure. It will include all jobs on the specified cluster that were in a running (R) or pending (PD) state during the time interval, including both the start and end date. Selecting an end date in the future will display the projection of currently running and pending jobs for their requested duration into the future.
Displaying usage over an extended time period into the future

If you select an end time after the present time, the figure will have a transparent red area overlaid on the future time labelled Projection. In this projection period, each job is assumed to run to the time limit requested for it. For queued resources, the projection supposes that each pending job starts at the beginning of the projected time (that is, right now) and runs until its requested time limit. This is not intended to be a forecast of actual future events!
Metrics, summation, and running jobs

Use the Metric pull-down control in the Parameters panel to select from the following metrics: CPU, CPU-equivalent, RGU, RGU-equivalent, Memory, Billing, gpu, and all specific GPU models available on the selected cluster.
The Summation pull-down allows you to switch between the daily Total and Running total. If you select Total, each bar of the histogram represents the total usage in that one day. If you select "Running total", each bar represents the sum of that day's usage and all previous days back to the beginning of the time interval. If the Allocation Target is displayed, it is similarly adjusted to show the running total of the target usage. See the next section for more.
If you set Include Running jobs to No, the figure shows only data from records of completed jobs. If you set it to Yes it includes data from running jobs too.
Display of the running total of account usage

When displaying the running total of the usage for a single account along with the Allocation target the usage histogram displays how an account deviates from its target share over the period displayed. The values in this view are the cumulative sum across days from "total" summation view for both the usage and allocation target. When an account is submitting jobs that request more than the account’s target share, it is expected that the usage cumulative sum will oscillate above and below the target share cumulative sum if the scheduler is managing fair share properly. Because the scheduler uses a decay period for the impact of past usage, a good interval to use to inspect the scheduler’s performance in maintaining the account's fair share is to display the past 30 days.
Visionner l'utilisation des ressources dans CCDB

Vous pouvez visionner les données d’utilisation des ressources par votre groupe en sélectionnant Mon compte --> Utilisation par le groupe dans la base de données CCDB.

Les valeurs pour l’utilisation des CPU (cœurs-année) et des GPU-année sont calculées selon la quantité des ressources allouées aux tâches exécutées sur les grappes. Notez que les valeurs employées dans les graphiques ne représentent pas les équivalents-cœur; ainsi, l’utilisation par les tâches qui exigent beaucoup de mémoire ne correspond pas à l’utilisation du compte représentée par l’ordonnanceur de la grappe.
La première barre d’onglets offre les vues suivantes :
- Par ressource de calcul; nom de la grappe sur laquelle les tâches ont été soumises,
- Par projet (RAPI); projets auxquels les tâches ont été soumises,
- Par utilisateur; utilisatrice ou utilisateur ayant soumis les tâches,
- Utilisation du stockage; voyez Stockage et gestion des fichiers.
Utilisation par ressource de calcul
Cette vue montre l’utilisation par ressource de calcul par grappe, pour tous les groupes desquels vous êtes propriétaire ou membre, pour l’année d’allocation en cours qui commence le 1er avril. Les données représentent l’utilisation à jour et supposent que cette utilisation restera la même jusqu’à la fin de l’année d’allocation.

Dans la colonne Extra Info, cliquez sur Utilisation sur une base mensuelle pour obtenir la répartition mensuelle pour la ressource correspondante. En cliquant sur Utilisation par utilisateur, la répartition se fait par utilisateur ou utilisatrice ayant soumis les tâches.
Utilisation par projet

Pour cette vue, une troisième barre d'onglets permet de sélectionner l'identifiant de projet pour l'année d'allocation choisie. Le tableau montre les détails pour chaque projet ainsi que les ressources utilisées sur toutes les grappes. Dans le haut de la vue, on trouve le nom du compte (par exemple def-, rrg- ou rpp-*, etc.), le titre du projet et le ou la propriétaire, ainsi que les sommaires de l'allocation et de l'utilisation.
Utilisation des GPU en unités GPU de référence (UGR)

Pour chaque projet (RAPI) ayant une utilisation de GPU, le détail d'utilisation par modèle de GPU est donné en GPU-années et en UGR-années dans une table située au bas de la page.
Utilisation par utilisateur

Cette vue montre l'utilisation par utilisatrices et utilisateurs ayant soumis des tâches pour le projet sélectionné (comptes de groupes), par système. En cliquant sur le nom d'une personne en particulier, vous obtiendrez son utilisation répartie par grappe. Tout comme les sommaires pour les groupes, vous pouvez utiliser l'option Utilisation sur une base mensuelle.