* Les UGR sont comptabilisés si un groupe utilise plus de UGR que de cœurs OU de mémoire par bundle. Prenons l'exemple d'un usager demandant 2 GPU (de 1 UGR chacun), 3 cœurs et 4Go de mémoire. La tâche exige donc l'équivalent de 2 bundles pour les GPU, mais un seul pour les cœurs et la mémoire. Pour calculer la priorité, l’ordonnanceur évalue la demande à 2 équivalents-UGR.
* Les GPU sont comptabilisés si un groupe utilise plus de GPU que de cœurs OU plus de mémoire que de bundles avec GPU.
*:Dans la figure 5, on demande 2 GPU , 6 cœurs et 32Go de mémoire. La tâche exige donc 2 équivalents-GPU pour les cœurs, mais un seul bundle pour la mémoire. Pour calculer la priorité, l’ordonnanceur évalue la demande à 2 équivalents-GPU.
Une allocation est l’attribution d’une quantité de ressources à un groupe de recherche pour une période donnée, habituellement un an. Nous gérons des ressources de stockage et des ressources de calcul à l’intention des chercheurs canadiens.
L’allocation des ressources de stockage attribue un maximum déterminé d’espace réservé à l’usage exclusif d’un groupe de recherche. Pour sa part, l’allocation des ressources partagées que sont les cœurs-année et les GPU-année est plus complexe puisque ces ressources sont partagées par l’ensemble des groupes et que l’allocation tient compte de l’utilisation moyenne de chaque groupe.
La durée de l’allocation est une valeur de référence utilisée pour le calcul de la moyenne de la consommation des ressources au cours de la période pendant laquelle celles-ci sont disponibles. Par exemple, si les grappes ne sont pas disponibles pour une semaine dû à des opérations de maintenance, les groupes de recherche touchés n’obtiennent pas une semaine additionnelle en compensation à la fin de la période. De la même manière, si la période d’allocation est allongée, les groupes n’y perdent pas en utilisation.
Notons qu’une allocation de cœurs-année et de GPU-année en ressources partagées considère la moyenne d’utilisation cible dans le temps; un groupe est donc plus susceptible d’atteindre et même de dépasser ses cibles en utilisant ses ressources de façon régulière sur la période qu’en soumettant des tâches en rafale (burst) ou en les reportant à plus tard.
De l'allocation à l'ordonnancement par priorité
Les ressources de calcul par cœurs-année et par GPU-année reçoivent des tâches qui sont immédiatement prises en charge par l’ordonnanceur. Rappelons qu’une tâche se compose d’une application logicielle et de la liste des ressources pour l’exécuter. L’ordonnanceur est aussi une application logicielle dont le rôle est de calculer la priorité de chaque tâche et de lui attribuer les ressources nécessaires selon leur disponibilité et en accord avec les règles de priorisation.
À l’aide d’algorithmes spécialisés, l’ordonnanceur tient compte des cibles de chaque groupe et compare la consommation récente du groupe à l’utilisation qui lui était allouée. Un des facteurs déterminants est la consommation à l’intérieur de la période. Le facteur qui possède cependant le plus de poids est la consommation (ou la non-consommation) récente, ceci en vue d’offrir une opération plus stable aux groupes dont l’utilisation réelle se rapproche des ressources qui leur étaient allouées. Cette façon de procéder assure une meilleure répartition du parc de ressources pour l’ensemble des groupes et fait en sorte qu’il est théoriquement possible pour tous les groupes d’atteindre leurs cibles.
Conséquences d'une surutilisation d'une allocation CPU ou GPU
Rien de grave ne se produira. Ces allocations sont une quantité cible de CPU ou de GPU que vous pouvez utiliser. Si vous avez des tâches en attente et qu’à ce moment la demande en ressources de calcul est basse, l’ordonnanceur pourrait faire exécuter vos tâches même si vous dépassez la quantité cible de votre allocation. Tout ce qui peut se produire alors serait que les prochaines tâches que vous soumettrez se voient attribuer un plus bas niveau de priorité que celles soumises par des groupes qui n’ont pas encore atteint leur niveau cible d’utilisation. Aucune tâche soumise à l’ordonnanceur n’est refusée en raison d’une surutilisation de ressources et votre utilisation moyenne de ressources sur la période d’allocation devrait se situer proche de la cible qui vous a été allouée.
Il se pourrait qu’au cours d’un mois ou d’une année vous puissiez accomplir plus de travail que votre allocation ne semblerait le permettre, mais ce scénario est peu probable puisque la demande est plus élevée que la quantité de ressources dont nous disposons.
Unités GPU de référence
Cette nouvelle unité sera utilisée à partir du CAR 2024.
As you may be aware, the performance of GPUs has dramatically increased in the recent years and is expected to do so again with the upcoming next generation of GPUs. Until RAC 2023, in order to reduce complexity, we have been treating all GPUs as equivalent to each other at allocation time and when considering how many resources groups have consumed. This has raised issues of fairness, both in the allocation process and while running jobs. We cannot continue to treat all GPU types as the same.
To overcome the fairness problem, we have defined a reference GPU unit (or RGU) in order to be able to rank all GPU models in production. Because roughly half of our users use primarily single-precision floating-point operations (FP32), the other half use half-precision floating-point operations (FP16), and a significant portion of all users care about the memory on the GPU itself, we set the following evaluation criteria with their corresponding weight:
Critères d'évaluation
Poids (UGR)
Score FP32
40% * 4 = 1.6
Score FP16
40% * 4 = 1.6
Score mémoire GPU
20% * 4 = 0.8
For convenience, weights are based on percentages up-scaled by a factor of 4 reference GPU units (RGUs). Then, by using the A100-40gb as the reference GPU model, we get the following scores for each model:
Score FP32
Score FP16
Score mémoire
Score pondéré
Poids:
1.6
1.6
0.8
(UGR)
Modèle
P100-12gb
0.48
0.00
0.3
1.0
P100-16gb
0.48
0.00
0.4
1.1
T4-16gb
0.42
0.21
0.4
1.3
V100-16gb*
0.81
0.40
0.4
2.2
V100-32gb*
0.81
0.40
0.8
2.6
A100-40gb
1.00
1.00
1.0
4.0
A100-80gb*
1.00
1.00
2.0
4.8
(*) On Graham, these GPU models are available through a very few contributed GPU nodes. While all users can use them, they are not allocatable through the RAC process.
As an example, the oldest GPU model in production (P100-12gb) is now worth 1.0 RGU. The next few generations of GPUs will be compared to the A100-40gb using the same formula.
Choisir des modèles de GPU pour votre projet
The relative scores in the above table should give you a hint on the models to choose. Here is an example with the extremes:
If your applications are doing primarily FP32 operations, an A100-40gb GPU is expected to be twice as fast as a P100-12gb GPU, but the recorded usage will be 4 times the resources. Consequently, for an equal amount of RGUs, P100-12gb GPUs should allow you to run double the computations.
If your applications (typically AI-related) are doing primarily FP16 operations (including mixed precision operations or using other floating-point formats), using an A100-40gb will result in getting evaluated as using 4x the resources of a P100-12gb, but it is capable of computing ~30x the calculations for the same amount of time, which would allow you to complete ~7.5x the computations.
During the Resource Allocation Competition 2024 (RAC 2024), any proposal asking for GPUs will require to specify the preferred GPU model for the project. Then, in the CCDB form, the amount of reference GPU units (RGUs) will automatically be calculated from the requested amount of gpu-years per year of project.
For example, if you select the narval-gpu resource and request 13 gpu-years of the model A100-40gb, the corresponding amount of RGUs would be 13 * 4.0 = 52. The RAC committee would then allocate up to 52 RGUs, depending on the proposal score. In case your allocation must be moved to Cedar, the committee would instead allocate up to 20 gpu-years, because each V100-32gb GPU is worth 2.6 RGUs (and 52 / 2.6 = 20).
For job scheduling and for usage accounting on CCDB, the use of reference GPU units will take effect on April 1st, 2024, with the implementation of RAC 2024.
Effet détaillé de l'utilisation des ressources sur la priorité
Le principe gouverneur dans notre façon de déterminer la priorité des tâches de calcul se base sur les ressources qu’une tâche rend non disponibles aux autres utilisateurs plutôt que sur les ressources effectivement utilisées.
Le cas de cœurs non utilisés qui influent sur le calcul des priorités se produit souvent lorsqu’une tâche est soumise en demandant plusieurs cœurs, mais n’en consomme effectivement qu’une partie à l’exécution. C’est le nombre de cœurs demandés par une tâche qui a une incidence sur la priorisation des prochaines tâches puisque la tâche bloque les cœurs non utilisés pendant son exécution.
Un autre cas fréquent de cœurs non utilisés se pose lorsqu’une tâche exige plus de mémoire que celle demandée pour un cœur. Sur une grappe où chaque cœur serait doté de 4Go de mémoire, une tâche qui demanderait un seul cœur et 8Go de mémoire bloquerait donc 2 cœurs et le deuxième cœur ne serait pas disponible pour les tâches des autres groupes de recherche
Équivalents-cœurs utilisés par l'ordonnanceur
Un équivalent-cœur se compose d’un cœur simple et d’une certaine quantité de mémoire; pour le nommer, nous utilisons le terme bundle. En plus du cœur, le bundle contient aussi la mémoire considérée comme étant associée à ce cœur.
Figure 1 – Équivalent-cœur sur Cedar et Graham
Cedar et Graham offrent surtout des cœurs de 4Go et dans leur cas, l’équivalent-cœur est un bundle de 4 Go (voir Figure 1). Pour sa part, Niagara offre surtout des cœurs de 4.8Go, donc des bundles de 4.8Go. L’utilisation des ressources par une tâche est comptabilisée à raison de 4Go ou 4.8Go par cœur, comme mentionné ci-dessus.
Le suivi des cibles s’avère relativement simple quand les ressources demandées sont des cœurs et des quantités de mémoire qui correspondent à un équivalent-cœur entier, plutôt qu’à une portion d’équivalent-cœur. Les choses se compliquent parce que l’utilisation de portions d’équivalents-cœur risque d’augmenter le pointage servant au calcul de la juste part du groupe de recherche. En pratique, la méthode appliquée résout le problème d'équité ou de perception d'équité, mais cette méthode n’est pas intuitive au début.
Dans les exemples qui suivent, la mémoire est de 4Go.
Comptabilisation par équivalents-cœur
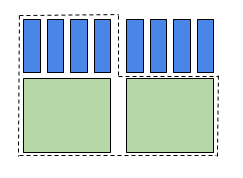
Examinons le cas où nous avons un bundle composé de 1 cœur et 4Go de mémoire.
Figure 2 – Deux équivalents-cœur Les cœurs sont comptabilisés si un groupe utilise plus de cœurs que de mémoire, c’est-à-dire plus que le ratio 1cœur/4Go.
Dans la figure 2, on demande 2 cœurs et 2Go par cœur pour une mémoire totale de 4Go; la tâche exige 2 équivalents-cœur pour les cœurs, mais un seul bundle pour la mémoire. Pour calculer la priorité, l’ordonnanceur évalue la demande à 2 équivalents-cœur.
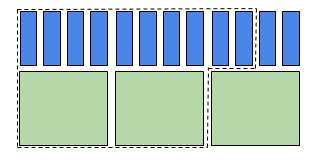
Figure 3 – 2.5 équivalents-cœur La mémoire est comptabilisée si un groupe utilise plus de mémoire que le ratio de 1 cœur/4Go.
Dans la figure 3, on demande 2 cœurs et 5Go par cœur pour une mémoire totale de 10Go; la tâche exige 2.5 bundles pour les cœurs. Pour calculer la priorité, l’ordonnanceur évalue la demande à 2.5 équivalents-cœur.
Équivalents-UGR utilisés par l'ordonnanceur
Les principes appliqués pour les équivalents-cœur valent aussi pour les GPU et les ressources qui leur sont associées. Une difficulté surgit cependant parce qu’il est important de différencier les cibles allouées pour la recherche sur GPU des cibles allouées pour la recherche qui n’utilise pas les GPU si nous voulons respecter les cibles d’allocation dans chacun des cas. Autrement, un chercheur n’utilisant pas les GPU ne pourrait pas utiliser les cibles qui lui sont allouées pour le parc de ressources GPU, ce qui créerait une surcharge, empêchant les chercheurs qui utilisent les GPU d’atteindre leurs cibles, et vice versa.
Le calcul de priorité se fait en fonction du nombre maximum de bundles UGR-coeurs-mémoire demandés. Examinons le cas où nous avons un bundle de 1 UGR, 3 cœurs et 4Go de mémoire.
Figure 4 - 1 équivalent-UGR
Les UGR sont comptabilisés si un groupe utilise plus de UGR que de cœurs OU de mémoire par bundle. Prenons l'exemple d'un usager demandant 2 GPU (de 1 UGR chacun), 3 cœurs et 4Go de mémoire. La tâche exige donc l'équivalent de 2 bundles pour les GPU, mais un seul pour les cœurs et la mémoire. Pour calculer la priorité, l’ordonnanceur évalue la demande à 2 équivalents-UGR.
Figure 5 – 2 équivalents-UGR
Les cœurs sont comptabilisés si un groupe utilise plus de cœurs que de GPU OU plus de mémoire par bundle avec GPU.
Dans la figure 6, on demande 1 GPU, 9 cœurs et 32Go; la requête exige donc 1.5 bundle avec GPU pour les cœurs, mais un seul bundle pour les GPU et la mémoire. Pour calculer la priorité, l’ordonnanceur évalue la demande à 1.5 équivalent-GPU.
Figure 6 – 1.5 équivalent-GPU (cœurs)
La mémoire est comptabilisée si un groupe utilise plus de mémoire que de GPU OU de cœurs par bundle avec GPU.
Dans la figure 7, on demande 1 GPU, 6 cœurs et 48Go; la requête exige donc 1.5 bundle avec GPU pour la mémoire, mais un seul bundle pour les GPU et les cœurs. Pour calculer la priorité, l’ordonnanceur évalue la demande à 1.5 équivalent-GPU.
Figure 7 – 1.5 équivalent-GPU (mémoire)
On the same fictive cluster, a bundle with one V100-32gb GPU, 7.8 CPU cores and 10.4 GB of memory is worth 2.6 RGU equivalents:
Figure 8 - 2.6 RGU equivalents, based on the V100-32gb GPU.
On the same fictive cluster, a bundle with one A100-40gb GPU, 12 CPU cores and 16 GB of memory is worth 4.0 RGU equivalents:
Figure 9 - 4.0 RGU equivalents, based on the A100-40gb GPU.
(*) These GPU models are available through a very few contributed GPU nodes. While all users can use them, they are not allocatable through the RAC process.
Note: While the scheduler will compute the priority based on the usage calculated with the above bundles, users requesting multiple GPUs per node also have to take into account the physical ratios.
Visionner les données d’utilisation par les groupes
Onglet Mon compte, option Utilisation par le groupe
Vous pouvez visionner les données d’utilisation des ressources par votre groupe en sélectionnant Mon compte --> Utilisation par le groupe dans la base de données CCDB.
Utilisation de CPU et de GPU, par ressource de calcul
Les valeurs pour l’utilisation des CPU (cœurs-année) et des GPU-année sont calculées selon la quantité des ressources allouées aux tâches exécutées sur les grappes. Notez que les valeurs employées dans les graphiques ne représentent pas les équivalents-cœur; ainsi, l’utilisation par les tâches qui exigent beaucoup de mémoire ne correspond pas à l’utilisation du compte représentée par l’ordonnanceur de la grappe.
La première barre d’onglets offre les vues suivantes :
Par ressource de calcul; nom de la grappe sur laquelle les tâches ont été soumises,
Par projet (RAPI); projets auxquels les tâches ont été soumises,
Par utilisateur; utilisatrice ou utilisateur ayant soumis les tâches,
Cette vue montre l’utilisation par ressource de calcul par grappe, pour tous les groupes desquels vous êtes propriétaire ou membre, pour l’année d’allocation en cours qui commence le 1er avril. Les données représentent l’utilisation à jour et supposent que cette utilisation restera la même jusqu’à la fin de l’année d’allocation.
Utilisation mensuelle par ressource
Dans la colonne Extra Info, cliquez sur Utilisation sur une base mensuelle pour obtenir la répartition mensuelle pour la ressource correspondante. En cliquant sur Utilisation par utilisateur, la répartition se fait par utilisateur ou utilisatrice ayant soumis les tâches.
Utilisation par projet
Utilisation par projet, avec répartition mensuelle
Pour cette vue, une troisième barre d'onglets permet de sélectionner l'identifiant de projet pour l'année d'allocation choisie. Le tableau montre les détails pour chaque projet ainsi que les ressources utilisées sur toutes les grappes. Dans le haut de la vue, on trouve le nom du compte (par exemple def-, rrg- ou rpp-*, etc.), le titre du projet et le ou la propriétaire, ainsi que les sommaires de l'allocation et de l'utilisation.
Utilisation par utilisateur
Utilisation de CPU et GPU
Cette vue montre l'utilisation par utilisatrices et utilisateurs ayant soumis des tâches pour le projet sélectionné (comptes de groupes), par système. En cliquant sur le nom d'une personne en particulier, vous obtiendrez son utilisation répartie par grappe. Tout comme les sommaires pour les groupes, vous pouvez utiliser l'option Utilisation sur une base mensuelle.




.png)
.png)
.png)






